
Taalas - стартап который засунул нейросеть прямо в чип и ускорил ИИ в 10 раз
Канадский стартап Taalas взял нейросеть Llama 3.1, буквально впаял её в кремниевый чип и получил 17 000 токенов в секунду на одного пользователя. Для сравнения: топовая NVIDIA B200 выдаёт около 594 токенов в секунду на той же модели. Разница - почти в 30 раз.
Проблема: почему ИИ до сих пор медленный и дорогой
Массовое внедрение ИИ сдерживается двумя барьерами:
- Высокая задержка - модели отвечают медленнее, чем работает человеческое мышление. Между вопросом и началом ответа проходит заметная пауза
- Огромные затраты - развёртывание требует дата-центров с GPU за десятки тысяч долларов, жидкостного охлаждения и мегаватт энергии
Корень проблемы - "стена памяти": процессор постоянно бегает к оперативной памяти за весами модели, и именно это перемещение данных становится узким местом.
Решение: модель - это и есть компьютер
Основатель Taalas Любиша Байич (бывший архитектор AMD и NVIDIA, основатель Tenstorrent) предложил радикальную идею: вместо того чтобы запускать нейросеть как программу, превратить саму нейросеть в чип.
Веса модели физически впаиваются в кремниевые транзисторы. Данные больше никуда не перемещаются - они уже там, где происходят вычисления. Стена памяти исчезает.
Ключевые принципы:
- Отдельный чип под каждую модель - максимальная специализация
- Технология Compute-in-Memory (CIM) - вычисления прямо в памяти
- Нет HBM, нет 3D-стекирования, нет жидкостного охлаждения - полное упрощение
HC1: Llama 3.1 в кремнии
Первый продукт Taalas - чип HC1 с аппаратной версией Meta Llama 3.1 8B:
- 53 млрд транзисторов, техпроцесс TSMC 6nm, площадь 815 мм²
- Энергопотребление всего ~200 Вт (обычное воздушное охлаждение)
- Формат стандартной карты PCIe
- Поддержка fine-tuning через LoRA и настраиваемый размер контекста
Результаты в сравнении с конкурентами:
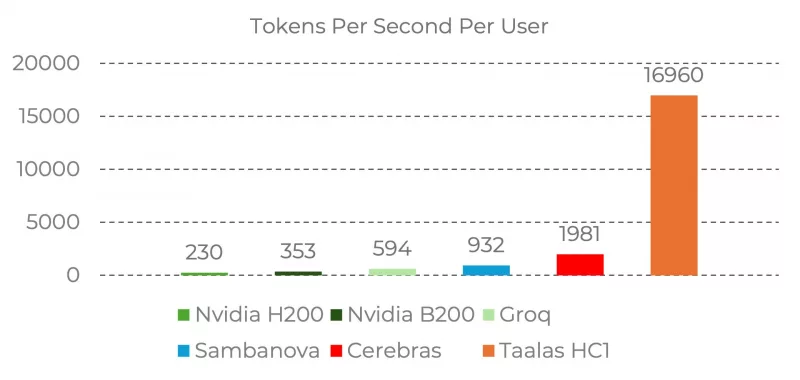
- Taalas HC1: ~17 000 tok/s
- Cerebras: ~1 981 tok/s
- Sambanova: ~932 tok/s
- Groq: ~594 tok/s
- NVIDIA B200: ~353 tok/s
- NVIDIA H200: ~230 tok/s
Итого: в 10 раз быстрее, в 20 раз дешевле, в 10 раз меньше энергии чем существующие решения.
Честно о подвохах
HC1 использует агрессивное квантование (3-bit/6-bit). На практике: скорость ответов реально впечатляет - текст появляется мгновенно. Но модель порой "туповата" - ответы менее точные и глубокие, чем от той же Llama на GPU в полной точности.
Второй нюанс - каждый чип навсегда привязан к одной модели. Нельзя загрузить другую нейросеть, как на GPU. Taalas обещает, что их платформа превращает любую модель в чип за 2 месяца, но это совсем другая история, чем просто обновить файл с весами.
ChatJimmy - попробуйте сами
Taalas запустили публичный демо ChatJimmy на реальном чипе HC1. Когда нажимаешь Enter, ответ появляется мгновенно - не "быстро", а буквально в тот же момент. Обработка промпта на скорости 15 000+ токенов в секунду.
Бывший CEO Stability AI Эмад Мостак написал: "Вы все должны попробовать чат-бот Taalas, я гарантирую, что вы сочтёте это безумным".
Для разработчиков также доступен API (по заявке).
Кто за этим стоит
За 2,5 года Taalas привлёк $219 млн инвестиций (Fidelity, Quiet Capital и др.). Команда - 25 инженеров из AMD, Apple, Google, NVIDIA и Tenstorrent.
Планы
- Весна 2026 - чип под среднеразмерную reasoning LLM (~20B параметров)
- Зима 2026-2027 - платформа второго поколения HC2 с фронтирной LLM
Если Taalas сможет запустить модель уровня GPT-4 в своём чипе, сохранив десятикратное преимущество в скорости - это будет настоящий прорыв.
Полезные ссылки
- ChatJimmy - демо-чат на базе чипа HC1
- Taalas API - заявка на доступ к API
- Taalas.com - официальный сайт


